
When people speak instead of typing, they say more, and say it differently. This study compared 252 AI-moderated interviews conducted in three modalities: voice, text, and hybrid (where respondents selected either voice or text per question).
Voice answers were 236% longer, 138% more diverse, and 28% richer in themes than typed ones. Yet, participants rated all modalities equally high for ease, empathy, and willingness to open up. Still, 55% preferred typing, citing privacy and control.
Voice yields richer stories; text feels safer; hybrid offers both.
AI-Moderated Interviews (AIMIs) are Glaut’s method for scaling open-ended research through AI-driven conversation. This experiment is part of our ongoing Research on Research program, designed to test how AIMIs perform across different data collection formats, from surveys to in-depth interviews.
Previous research shows that when people speak, they disclose more detail and emotion. We wanted to test if that still holds true when the interviewer is AI, and if richer always means better.
Respondents who spoke their answers gave substantially longer and richer responses than those who typed. On average, voice responses contained 236% more words than text responses, suggesting that verbal expression encourages elaboration and storytelling.
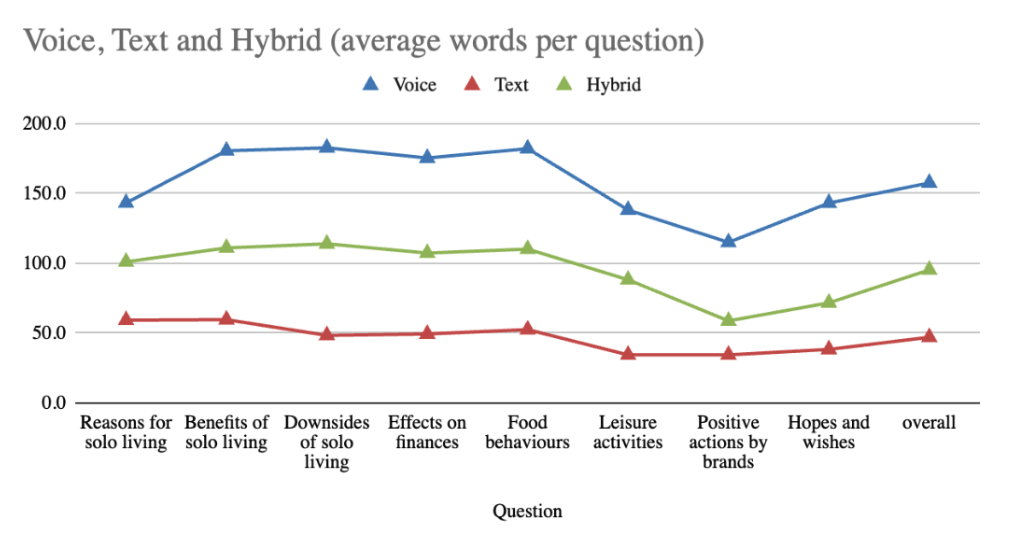
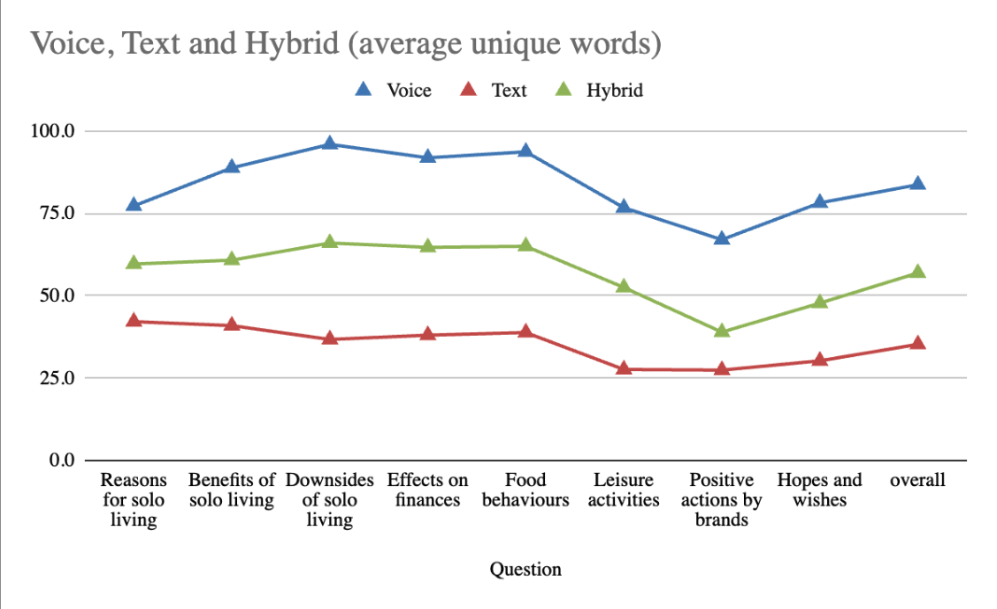
Voice responses were 138% more lexically diverse, reflecting broader conceptual range and spontaneity; hybrid participants were intermediate.
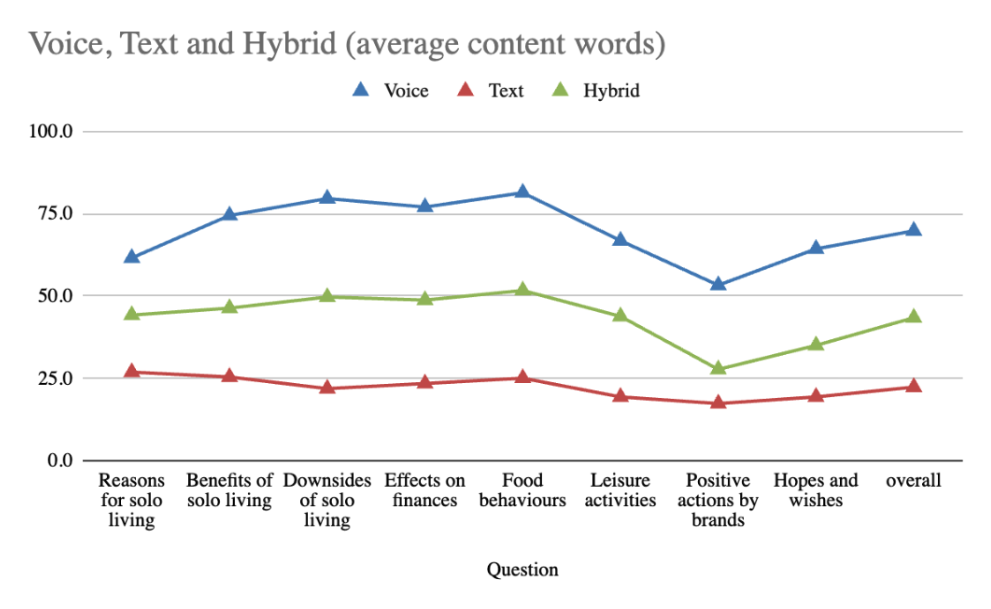
When it came to descriptiveness, the difference widened even further. Voice participants used 213% more content words - nouns, verbs, and adjectives that add specificity and depth - than those who typed their answers.
Finally, thematic analysis revealed that voice interviews generated an average of 27 distinct themes per participant, compared to 21 in text and 23 in hybrid.
In short: people who speak think aloud in stories; those who type think in summaries.
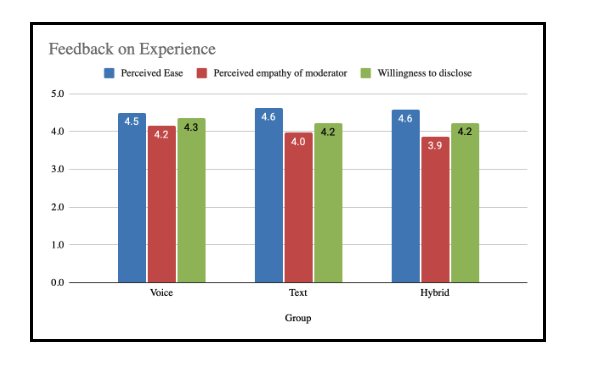
Despite these linguistic differences, the overall interview experience remained remarkably consistent across modalities. Participants rated ease of use (4.6/5), AI empathy (4.1/5), and willingness to disclose (4.2/5) almost identically, suggesting that AIMIs can deliver a stable and engaging experience whether users speak or type.
When asked which format they would choose next time, 55% preferred text, mainly for privacy and control.
Voice was appreciated for its speed, naturalness, and emotional connection, while hybrid participants, who could switch between text and voice with each question, rarely switched modes once they started, suggesting people quickly find and stick to a preferred way of communicating.
The result shows a key trade-off: voice yields richer data, text ensures comfort, and hybrid AIMIs offer a balance.
Voice enhances data richness, making it ideal for exploratory or generative research when you need depth, emotion, and narrative.
Text enhances comfort and scalability, useful for sensitive topics or large-scale studies.
Hybrid AIMIs balance the two, allowing participants to select either modality per question and giving researchers methodological flexibility without sacrificing consistency.
"Modality is not a neutral choice; it’s part of your research design.”
V. Valli, AI Researcher, Glaut
This experiment is part of Glaut’s open Research on Research series.
Next, we’re comparing AI-moderated vs. human-moderated interviews to understand how empathy and spontaneity differ across moderators.
If you’re a research partner or an academic interested in collaborating, reach out.
Collect, analyze, and report research from any source with more depth, speed, and control.
Schedule a free demo







