
.png)
Online surveys are efficient, scalable, and familiar. However, when the research question relies on open-ended responses - motivations, barriers, lived experiences - many survey responses are 1-word, short, generic, or unusable. AI-moderated interviews (AIMIs) promise a different experience: a conversational format that can adapt follow-ups based on what the participant actually said.
To test whether that promise results in clearly better data, Aylin Idrizovski with support from Dr. Florian Stahl from the Chair of Quantititative Marketing & Consumer Analytics, University of Mannheim, conducted a comparative study. In this study, AIMIs and static surveys gathered responses to the same questionnaire from comparable samples under controlled conditions. We at Glaut Research only provide the platform free of charge and cover the panel costs.
The study had a clear methodological aim: to assess whether AI-moderated interviews (AIMI) produce higher-quality data than static online surveys when both formats collect answers to the same questionnaire.
More specifically, the team evaluated differences across four dimensions:

This was a between-subjects experiment (participants completed one format only), chosen to avoid learning or carryover effects. Participants were recruited via PureSpectrum and screened to include U.S. citizens aged 18–55, with a balanced gender distribution and an interest in health and fitness.
Both groups answered the same questionnaire on healthy lifestyle choices:
The topic itself was not the object of analysis; the study focused on the methodological differences between the formats.
This is the core manipulation:
Because AIMIs can go beyond two follow-ups, the analysis used only the first two AIMI follow-ups to keep comparability high.
Both formats flagged incomplete/abandoned sessions and retained only complete responses. Additionally, the AIMI condition used an uncooperative-response detector and excluded low-quality inputs during cleaning, whereas the SoSci condition retained gibberish to reflect real-world vulnerability to invalid entries.
The study evaluated response quality using three measurement blocks:
Computed from open-ended responses (including follow-ups), the linguistic measures included:
Using an inductive codebook (Appendix C), the team measured:
A 7-item Likert scale captured perceived:
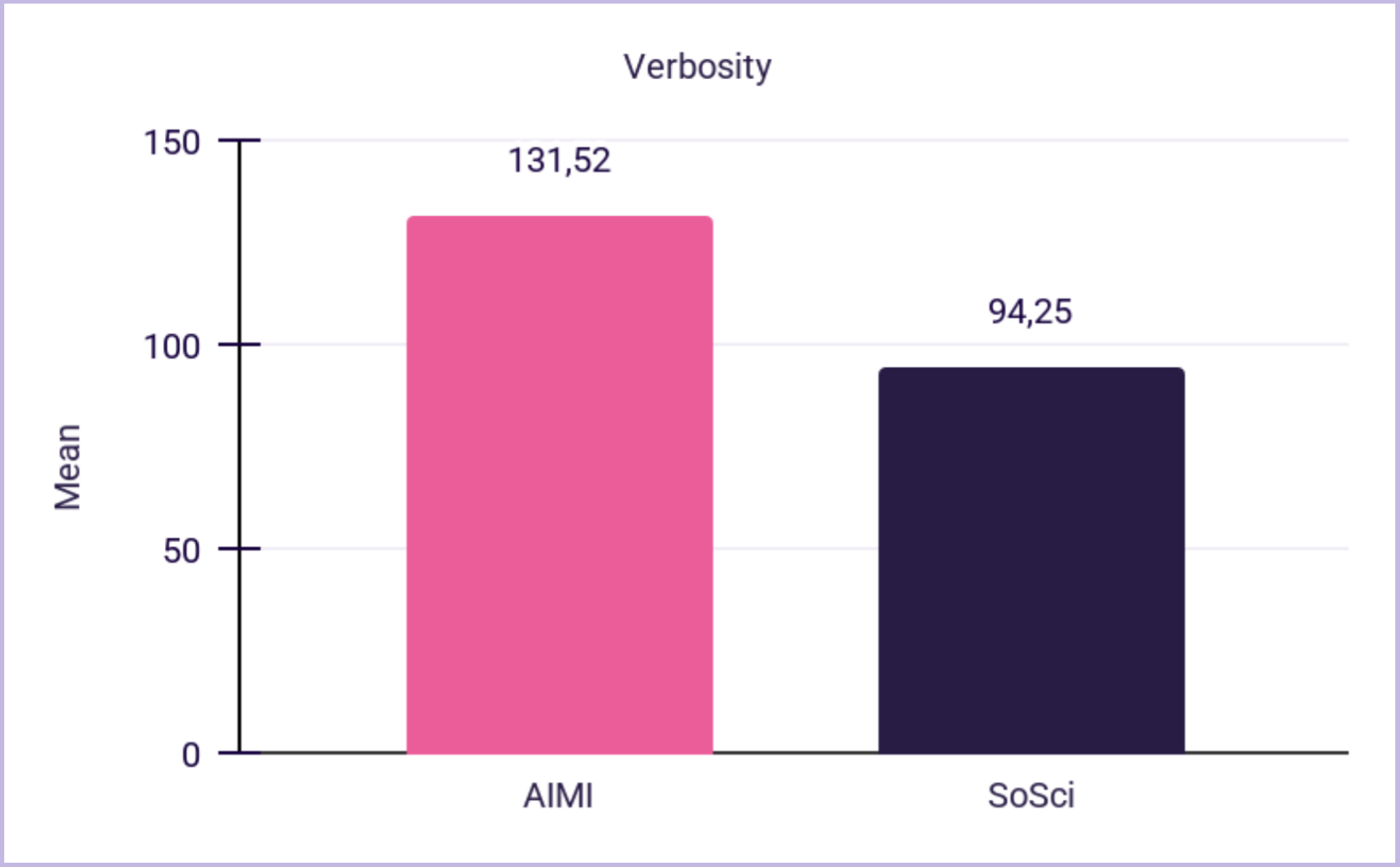
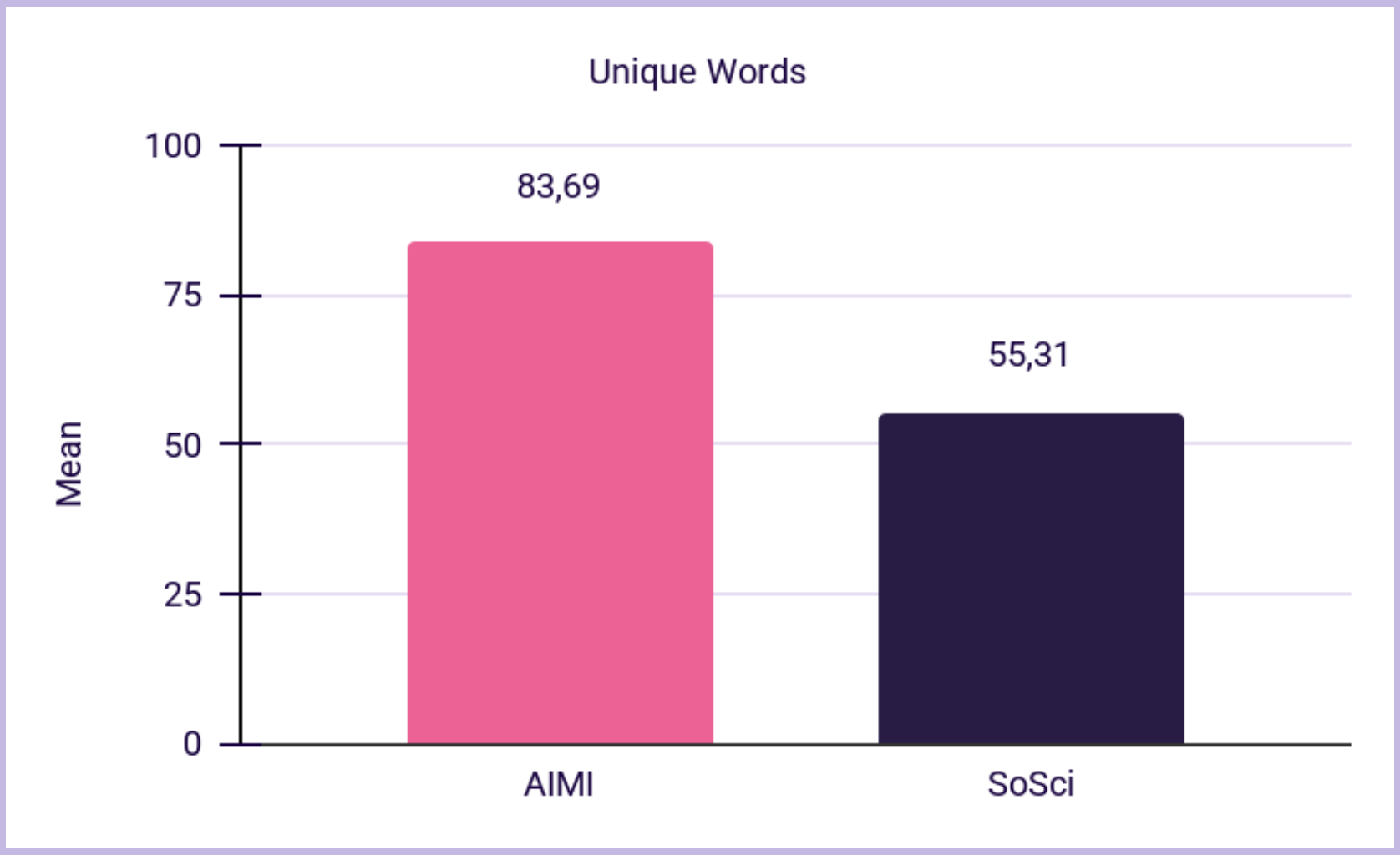
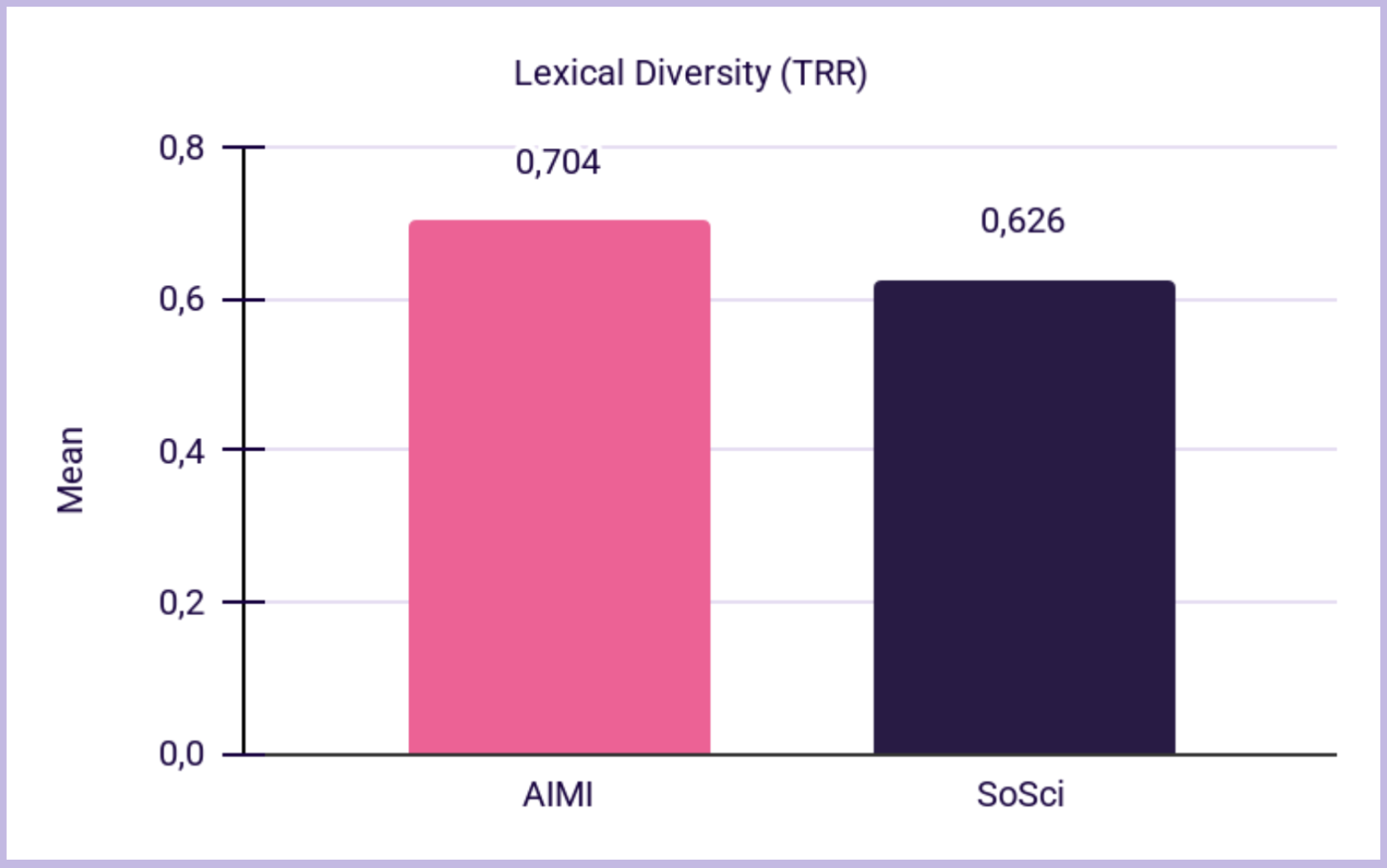
Across multiple measures, AIMI responses were richer:
Importantly, this was not “more text at any cost.” On clarity-related measures, the formats were statistically equivalent:
Interpretation: AIMIs generated longer, more varied responses without sacrificing readability or content density, which is essential when “richer” responses could otherwise become rambling.
The thematic analysis separates quantity from diversity.
Why this is important: If AIMI had simply added more words, we would see an increase in theme count (more words → more mentions). However, the total mentions remained roughly the same while the variety of ideas widened. This indicates that AIMI’s conversational probing encouraged a wider exploration of topics, rather than just producing longer responses.
A common issue with open-ended responses is the proportion that are not interpretable, such as random characters, repeated words, non-English strings, or extremely short nonsense answers.
In this dataset:
Interpretation: This study found nonsensical input exclusively in surveys. This differentiation has practical benefits, reducing cleaning time and minimizing lost completes.
Participant experience improved overall in the AIMI condition:

At the item level, the advantages concentrate around interaction quality:
Ease of expression and comfort were consistent across formats, indicating AIMI’s improvements did not stem from making people feel pressured or uncomfortable, but rather from creating interactions that felt more responsive and diverse.
When two comparable samples answered the same questions:
In conclusion, this controlled comparison suggests that AIMI’s conversational and adaptive qualities improve data quality and participant experience while maintaining clarity.
Read the full paper here, or contact us at hello@glaut.com
Collect, analyze, and report research from any source with more depth, speed, and control.
Schedule a free demo







